مقدمة عن أداة ModelRed
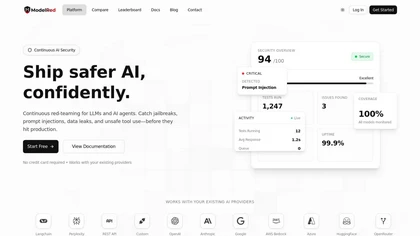
تُعد ModelRed منصة متخصصة في أمن الذكاء الاصطناعي (AI Security) والـ Red Teaming،
تهدف إلى كشف الثغرات ونقاط الضعف في نماذج الذكاء الاصطناعي، خصوصًا نماذج اللغة الكبيرة (LLMs)، قبل وصولها إلى مرحلة الإنتاج الفعلي.
تساعد ModelRed فرق
التطوير، وأمن المعلومات، وفرق الـ DevOps، والامتثال على بناء أنظمة ذكاء
اصطناعي موثوقة وآمنة، قادرة على مواجهة الهجمات المتقدمة مثل الهجمات بالبرومبت (Prompt Injection)، ومحاولات كسر القيود (Jailbreaks)، وتسريب البيانات الحساسة.
تعتمد المنصة على نهج الاختبارات الهجومية المستمرة (Continuous Red-Teaming)، حيث تقوم بمحاكاة هجمات واقعية ومتطورة على النموذج، بهدف اكتشاف الثغرات مبكرًا وتقديم أدلة قابلة لإعادة التشغيل، تساعد الفرق الفنية على فهم الخلل ومعالجته بشكل دقيق. كما أن ModelRed لا تتوقف عند مرحلة ما قبل النشر فقط، بل تستمر في مراقبة النماذج أثناء التشغيل الفعلي، لضمان حماية شاملة على مدار دورة حياة النموذج.
المميزات الأساسية لأداة ModelRed
1. اكتشاف الثغرات في نماذج الذكاء الاصطناعي
تتيح ModelRed اكتشاف وتحليل نقاط الضعف في نماذج الذكاء الاصطناعي قبل دخولها إلى بيئة الإنتاج.
تعمل المنصة على اختبار النموذج ضد مجموعة واسعة من السيناريوهات الهجومية، مما يساعد على منع:
تسريب البيانات الحساسة.
تجاوز سياسات الأمان والضوابط الأخلاقية.
إساءة استخدام النموذج لإنتاج مخرجات ضارة أو غير ملائمة.
هذا التركيز على الأمن الاستباقي يجعل المؤسسات أقل عرضة للمخاطر القانونية والتشغيلية.
2. Red Teaming مستمر ومتطور
تقدم ModelRed نظام Red Teaming مستمر يعتمد على أكثر من 10,000 نمط هجومي متطور يتم تحديثه وتوسيع نطاقه بشكل دوري.
هذه الهجمات الذكية تتكيف مع ردود النموذج، وتولد متغيرات جديدة للهجوم من أجل كشف الثغرات المخفية، مع تغطية شاملة لمخاطر OWASP LLM.
النتيجة: رؤية أعمق لمستوى أمان النموذج، مع تقارير وأدلة يمكن الرجوع إليها لاحقًا.
3. كاشف مخصص لـ LLM وإصدار أحكام قابلة للتكرار
تتضمن المنصة LLM Detector مخصص، يعمل على:
تحليل تفاعلات النموذج.
إصدار أحكام واضحة حول وجود هجمات مثل Prompt Injection أو Jailbreak.
تقديم نتائج قابلة لإعادة التشغيل والمراجعة (Reproducible Verdicts).
هذا يساعد فرق الأمن والامتثال على توثيق قراراتهم والاعتماد على أدلة قوية في تقارير التدقيق.
4. اكتشاف Prompt Injection بدقة عالية
تعلن ModelRed عن تحقيق دقة تصل إلى %99.2 في اكتشاف أنماط التلاعب بالبرومبت ومحاولات اختطاف السياق (Context Hijacking).
يتم ذلك عبر:
خوارزميات تعتمد على الأنماط (Pattern-Based).
تحليلات دلالية متقدمة (Semantic Heuristics).
وبهذا تستطيع المنصة حماية النماذج من محاولات إدخال تعليمات خبيثة أو التلاعب بسياق المحادثة.
5. منع Jailbreak بسرعة استجابة عالية
تتيح ModelRed اختبار النماذج ضد هجمات Jailbreak المعقدة، والتي تحاول الالتفاف على القيود الأخلاقية والأمنية.
تتميز المنصة بـ:
زمن استجابة متوسط لحماية Jailbreak يبلغ حوالي 2.3 ميلي ثانية.
استخدام “سلاسل هجومية” وتوليد متغيرات تلقائية للهجمات لتقوية الحماية بمرور الوقت.
الهدف هو منع النموذج من إنتاج محتوى مخالف لسياسات الشركة أو معايير الأمان.
6. حزم اختبارات (Probe Packs) مُرقّمة ومُؤرشفة
توفر ModelRed ما يسمى بـ Versioned Probe Packs، وهي حزم من الاختبارات الهجومية والإستراتيجيات الأمنية يتم إصدارها بنسخ مختلفة.
هذا يسمح لك بـ:
مقارنة أداء الأمان بين إصدارات مختلفة من النموذج.
تتبع تحسن أو تراجع مستوى الأمان بمرور الوقت.
بناء سجل تاريخي للثغرات والإصلاحات.
7. تكامل مع أكثر من 15 مزود خدمة AI
تدعم ModelRed التكامل مع عدد كبير من مزودي خدمات الذكاء الاصطناعي، مثل:
OpenAI
Anthropic
Google
Azure
وغيرهم من مزودي خدمات الـ LLM، مما يجعلها منصة Vendor-Agnostic لا تعتمد على مزود واحد فقط.
8. تكامل مباشر مع CI/CD
يمكن دمج ModelRed مباشرة في خطوط CI/CD الخاصة بك، بحيث يتم:
تشغيل اختبارات الأمان تلقائيًا مع كل تغيير في الكود أو النموذج.
إيقاف أو منع عمليات الدمج (Merge) في حال اكتشاف مخاطر حرجة.
هذا يحول أمن الذكاء الاصطناعي إلى جزء أساسي من دورة التطوير، وليس خطوة جانبية أو يدوية.
9. SDK وواجهات برمجية سهلة الدمج
توفر ModelRed حزم تطوير (SDK) وواجهات API تسهل:
دمج المنصة في التطبيقات الحالية.
أتمتة اختبارات الأمان.
بناء لوحات تحكم داخلية لعرض نتائج الفحص والتقارير.
الاستخدامات العملية لأداة ModelRed
1. اكتشاف الثغرات قبل النشر (Pre-Deployment)
يمكن للفرق دمج ModelRed في بيئة التطوير لاكتشاف الثغرات قبل وصول النموذج إلى الإنتاج، مثل:
اختبار مخرجات النموذج ضد محاولات استخراج بيانات حساسة.
التأكد من التزام النموذج بسياسات المحتوى.
منع إدخال نموذج يعاني من نقاط ضعف خطرة إلى بيئة العملاء.
بهذا الشكل، تتحول ModelRed إلى "بوابة أمان" قبل النشر.
2. حماية نماذج الإنتاج في الوقت الفعلي
بعد النشر، يمكن لـ ModelRed العمل كطبقة حماية مستمرة أمام واجهات الـ API أو تطبيقات الدردشة:
مراقبة تفاعلات المستخدمين مع النموذج.
اكتشاف ومنع أكثر من %99.8 من التهديدات المكتشفة تلقائيًا.
حظر الطلبات الخبيثة أو إعادة صياغتها قبل وصولها للنموذج.
وهذا يضمن أن النظام يظل آمنًا حتى في مواجهة هجمات جديدة ومتطورة.
3. دعم الامتثال في القطاعات الحساسة
تُستخدم ModelRed في قطاعات حساسة مثل:
القطاع الصحي: لمنع تسريب بيانات المرضى ودعم الالتزام بمعايير مثل HIPAA.
الخدمات المالية: لحماية خوارزميات التداول والبيانات المالية وضمان عدم تسريب معلومات حساسة.
المؤسسات الساعية إلى SOC 2 أو ISO: عبر توفير تقارير أمان مفصلة وسجلات تدقيق واضحة.
4. دعم فرق الأمن وRed Team
يستفيد متخصصو الأمن وفرق الـ Red Team من:
مكتبة ضخمة من سيناريوهات الهجوم الجاهزة.
أدوات تحليل متقدمة لتقييم مدى استجابة النموذج للهجمات.
تقارير مفصلة تساعد على تقديم توصيات واضحة لفرق التطوير.
طريقة عمل ModelRed
يمكن تلخيص طريقة عمل ModelRed في عدة مراحل رئيسية:
الدمج (Integration)
توصيل ModelRed مع مزود خدمة الذكاء الاصطناعي (مثل OpenAI أو غيره).
ربطها مع خطوط CI/CD أو تطبيقات الإنتاج أو كليهما.
إعداد سيناريوهات الاختبار
اختيار حزم Probe Packs المناسبة لنوع النموذج وحالة الاستخدام.
تحديد سياسات الأمان والضوابط الأخلاقية وقوائم المحتوى الممنوع.
تشغيل اختبارات Red Teaming
إرسال آلاف الطلبات الهجومية الذكية إلى النموذج.
تحليل ردود النموذج وتحديد نقاط الضعف المحتملة.
توليد التقارير والأدلة
عرض نتائج مفصلة حول كل ثغرة مكتشفة.
توفير نماذج للطلبات والإجابات التي سببت الاختراق أو المشكلة.
المعالجة والتحسين
قيام فرق التطوير بضبط البرومبتات، أو الحماية، أو السياسات.
إعادة تشغيل الاختبارات للتحقق من حل المشاكل.
المراقبة المستمرة
استمرار ModelRed في مراقبة الطلبات الحية في الإنتاج.
اكتشاف أنماط الهجمات الجديدة وإضافتها تلقائيًا إلى مكتبة الهجمات.
لماذا تختار ModelRed؟
هناك عدة أسباب تجعل ModelRed خيارًا قويًا لأي فريق يعمل على نماذج ذكاء اصطناعي حساسة:
تكيّف مستمر مع التهديدات
المنصة لا تعتمد على اختبارات ثابتة، بل تكتشف أكثر من 10,000 نمط هجومي جديد شهريًا، مما يعني أن النظام يتطور مع الزمن بدل أن يتقادم.دقة عالية ووقت استجابة منخفض
دقة %99.2 في كشف Prompt Injection وزمن استجابة 2.3ms في منع Jailbreak يوفران حماية سريعة وفعالة دون التأثير الكبير على أداء النظام.تقليل الوقت والجهد على فرق الأمن
فرق الأمان غالبًا ما تعاني من ضغط كبير؛ تساعد ModelRed في تقليل وقت المراجعات اليدوية بما يصل إلى 30%، وتقليل التعرض للمخاطر بنسبة قد تصل إلى 25% خلال 90 يومًا وفقًا للحالات المبلغ عنها.مرونة في التكامل مع بيئتك الحالية
دعم لأكثر من 15 مزود خدمة، تكامل مع CI/CD، وتوفر SDK يجعل إدخال ModelRed في البنية الحالية أمرًا سلسًا بدون تغيير جذري للبنية التحتية.موجهة للفرق المتعددة داخل المؤسسة
فرق التطوير (Developers).
فرق الأمن والـ Red Team.
فرق DevOps.
فرق الامتثال والتدقيق.
كل فريق يمكنه الاعتماد على نفس المنصة، لكن بواجهات وتقارير تلبي احتياجاته.
الأسئلة الشائعة حول ModelRed
1. هل ModelRed مخصصة فقط لنماذج اللغة الكبيرة (LLMs)؟
تركز ModelRed بشكل
أساسي على نماذج اللغة الكبيرة لأنها الأكثر عرضة لهجمات البرومبت وكسر
القيود، لكنها يمكن أن تُستخدم أيضًا مع أنظمة ذكاء اصطناعي أخرى تعتمد على واجهات نصية أو تفاعلية.
2. هل تؤثر ModelRed على أداء النموذج أو سرعته؟
تم تصميم ModelRedلتعمل بزمن استجابة منخفض جدًا، خصوصًا في حماية Jailbreak، بحيث لا يُلاحظ المستخدم النهائي فرقًا كبيرًا في الأداء، مع الحفاظ على طبقة حماية
فعّالة.
3. هل يحتاج الفريق إلى خبرة أمنية متقدمة لاستخدام ModelRed؟
ليست بالضرورة، إذ توفر المنصة واجهات وتقارير سهلة الفهم مع إعدادات
جاهزة. ومع ذلك، وجود فريق أمن أو Red Team يساعد في الاستفادة القصوى من
قدرات المنصة المتقدمة.
4. هل يمكن استخدام ModelRed في بيئات سحابية وخاصة (On-Premise أو VPC)؟
بحسب إعداد المنصة، يمكن تشغيل ModelRed في بيئات سحابية أو ضمن بنية خاصة، مما يدعم المؤسسات التي تفرض متطلبات صارمة على مكان تخزين البيانات ومعالجتها.
5. كيف تساعد ModelRed في التدقيق والامتثال (Compliance & Audit)؟
توفر المنصة سجلًا واضحًا للهجمات، والنتائج، والإصلاحات، مما يجعل إعداد
تقارير الامتثال (مثل SOC 2 أو معايير القطاع المالي والصحي) أسهل وأكثر
دقة.
الخلاصة
ModelRed ليست مجرد أداة اختبار بسيطة، بل بنية تحتية أمنية كاملة لنماذج الذكاء الاصطناعي.
فهي تجمع بين:
Red Teaming مستمر ومتطور.
دقة عالية في كشف Prompt Injection وJailbreak.
تكامل عميق مع خطوط تطوير البرمجيات (CI/CD).
دعم متعدد المزودين ومرونة عالية في الدمج.
إذا كانت مؤسستك تعتمد على نماذج ذكاء اصطناعي في مجالات حساسة، أو تتعامل مع بيانات مهمة وسرية، فإن الاستثمار في ModelRed يمنحك ثقة أكبر في أمان أنظمتك، ويساعدك على الابتكار دون التضحية بالسلامة أو الامتثال.
لو أحببت، في الرسالة القادمة أستطيع أن أجهز لك وصفًا قصيرًا (Meta Description) وعناوين سيو جذابة لمقال ModelRed، بالإضافة لكلمات مفتاحية مقترحة.