-
مجاني + مدفوع
- زيارة الموقع
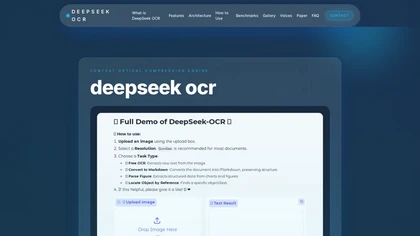
مقدمة عن أداة DeepSeek OCR
تُعد DeepSeek OCR واحدة من أحدث وأقوى أدوات الذكاء الاصطناعي المفتوحة المصدر في مجال التعرف الضوئي على النصوص (OCR) وتحليل المستندات الرقمية. تم تطوير هذه الأداة اعتمادًا على بنية Transformer المتقدمة، وهي تقدم ثورة حقيقية في كيفية تحويل الصفحات عالية الدقة إلى بيانات نصية وهيكلية دقيقة، مع الحفاظ على تخطيط المستندات الأصلية بما في ذلك الجداول والمخططات والصيغ الكيميائية.
بفضل اعتمادها على تقنية الضغط البصري السياقي (Context Optical Compression)، تستطيع الأداة ضغط الصور عالية الدقة إلى رموز بصرية مضغوطة دون فقدان كبير في الجودة، مما يتيح لها معالجة عدد هائل من الصفحات بسرعة وكفاءة. تعمل DeepSeek OCR بمعدل يقارب 200,000 صفحة يوميًا لكل وحدة GPU واحدة، مما يجعلها حلاً مثاليًا للمؤسسات الكبرى ومراكز الأرشفة الرقمية.
تدعم الأداة أكثر من 100 لغة، وتوفر دقة تقارب 97% في استخلاص النصوص والتخطيطات المعقدة، مما يجعلها خيارًا رائدًا لمشاريع الرقمنة، والبحث العلمي، وتحليل الوثائق التقنية. كما أن رخصة MIT المفتوحة تمنح المستخدمين مرونة كبيرة في النشر محليًا أو عبر واجهات API آمنة.
المميزات الأساسية
تأتي DeepSeek OCR بمجموعة من الخصائص التقنية المتقدمة التي تميزها عن أدوات OCR التقليدية، من أبرزها:
1. استخراج النصوص والتخطيطات عالية الدقة
تتميز الأداة بقدرتها على التعامل مع الصور والمستندات عالية الدقة، واستخلاص النصوص منها بدقة شبه تامة مع الحفاظ على التنسيق الأصلي. فهي تتعرف على الجداول والمخططات والمعادلات الرياضية والرموز العلمية، وتعيد إنتاجها بدقة متناهية.
2. بنية Transformer ثنائية المراحل
تستخدم DeepSeek OCR نموذجًا من مرحلتين:
المرحلة الأولى: تعتمد على مزيج من نموذج الرؤية SAM Transformer ومُشفر CLIP-Large، إضافة إلى ضاغط بصري متقدم يضغط الصفحة بمعدل 16×.
المرحلة الثانية: تستخدم نموذج DeepSeek-3B-MoE الذي يضم ما يقرب من 570 مليون معلمة نشطة لكل رمز لإعادة بناء النصوص والتخطيطات والرسومات بدقة شبه مثالية.
3. دعم أكثر من 100 لغة
بفضل قاعدة بيانات التدريب الضخمة التي تضم نصوصًا بأكثر من مائة لغة تشمل اللاتينية، والعربية، والصينية، واليابانية، والسيريلية، واللغات العلمية المتخصصة، تستطيع DeepSeek OCR التعامل مع مختلف أنواع المستندات العالمية بدقة عالية.
4. أداء استثنائي في السرعة والإنتاجية
يمكن للأداة معالجة ما يصل إلى 200 ألف صفحة يوميًا على وحدة GPU واحدة من نوع NVIDIA A100، مما يجعلها مثالية للمشاريع الضخمة التي تتطلب رقمنة أو تحليل كميات كبيرة من الوثائق بسرعة.
5. تنسيقات إخراج متعددة
تتيح الأداة للمستخدمين تصدير النتائج بعدة صيغ لتناسب مختلف الاستخدامات، مثل:
HTML للمواقع الإلكترونية،
Markdown للمدونات والتقارير التقنية،
JSON لتكامل البيانات في الأنظمة المختلفة،
SMILES لتمثيل الصيغ الكيميائية في الأبحاث العلمية.
6. الترخيص المفتوح (MIT License)
بفضل الترخيص المفتوح المصدر، يمكن استخدام DeepSeek OCR بشكل آمن داخل المؤسسات (on-premise) أو عبر واجهات API، مما يمنح الشركات المرونة في التخصيص وتكامل الأداة مع أنظمتها الخاصة.
الاستخدامات العملية
تفتح DeepSeek OCR آفاقًا واسعة للتطبيقات العملية في العديد من المجالات الأكاديمية والتقنية والإدارية، ومن أبرز استخداماتها:
✔️ رقمنة الوثائق التاريخية والمحفوظات
يمكن للباحثين ومراكز الأرشفة الرقمية استخدام DeepSeek OCR لتحويل الوثائق التاريخية القديمة إلى نصوص رقمية قابلة للبحث، مع الحفاظ على التنسيقات الأصلية والرسومات بدقة عالية.
✔️ أتمتة معالجة المستندات القانونية والعلمية
تُستخدم الأداة لتحويل آلاف الأوراق القانونية أو المقالات البحثية إلى ملفات HTML أو JSON منظمة وقابلة للبحث، مما يختصر ساعات العمل اليدوي ويقلل نسبة الخطأ.
✔️ تسريع إدخال البيانات في الشركات
تساعد DeepSeek OCR المؤسسات على أتمتة عملية إدخال البيانات من الفواتير والعقود والنماذج الورقية إلى أنظمة الإدارة الرقمية، مما يرفع كفاءة العمل ويقلل التكاليف التشغيلية.
✔️ تحليل المحتوى العلمي والتقني
بفضل دعمها للصيغ الكيميائية (SMILES) والمخططات الرياضية، يمكن للأداة أن تكون أداة لا غنى عنها في تحليل الأوراق العلمية والتقنية، خصوصًا في المجالات الهندسية والكيميائية والطبية.
✔️ تطوير تطبيقات الذكاء الاصطناعي المتقدمة
يمكن للمطورين دمج DeepSeek OCR في تطبيقاتهم الذكية التي تتطلب فهمًا بصريًا ونصيًا للمستندات، مثل أدوات البحث الدلالي أو تطبيقات الأرشفة الذكية.
طريقة العمل
تعمل DeepSeek OCR من خلال آلية دقيقة مكونة من مرحلتين متكاملتين:
المرحلة الأولى – الضغط البصري السياقي (Context Optical Compression)
تقوم الأداة بتحويل الصفحة ذات دقة 1024×1024 إلى 256 رمزًا بصريًا مضغوطًا فقط، مع الحفاظ على المعلومات البصرية الأساسية. هذه التقنية المبتكرة تقلل الحاجة إلى طاقة معالجة ضخمة مع الحفاظ على جودة النصوص والمخططات.المرحلة الثانية – إعادة بناء النصوص والتخطيطات
بعد عملية الضغط، يستخدم النموذج DeepSeek-3B-MoE (بنية الخبراء المتعددة) لتحليل الرموز البصرية وفهم محتواها اللغوي والبصري، مما يسمح بإعادة بناء المستند الأصلي بدقة شبه خالية من الأخطاء.
بفضل هذا النهج المبتكر، تجمع الأداة بين سرعة الأداء ودقة التحليل، مما يجعلها متفوقة على أنظمة OCR التقليدية التي تعتمد فقط على تحليل الصور دون فهم السياق الكامل للمحتوى.
لماذا تختار DeepSeek OCR؟
هناك العديد من الأسباب التي تجعل DeepSeek OCR الخيار المثالي للمؤسسات والباحثين الذين يسعون لحلول OCR متقدمة:
✅ دقة شبه تامة (≈97%) في استخلاص النصوص والتخطيطات.
✅ دعم لغوي شامل لأكثر من 100 لغة حول العالم.
✅ أداء فائق السرعة يصل إلى 200 ألف صفحة في اليوم.
✅ إخراج متعدد التنسيقات يناسب كل حالات الاستخدام.
✅ مفتوح المصدر ومرن في النشر بترخيص MIT.
✅ حفظ الهيكل المعقد للصفحات بما في ذلك الجداول والرسومات والمعادلات.
✅ كفاءة في استهلاك الموارد بفضل تقنية الضغط السياقي.
بكلمات أخرى، تجمع الأداة بين القوة الحسابية والذكاء التحليلي لتقديم نتائج احترافية تفوق التوقعات.
الأسئلة الشائعة حول DeepSeek OCR
❓ ما هو الهدف من أداة DeepSeek OCR؟
تهدف الأداة إلى تحويل المستندات الورقية أو الصور عالية الدقة إلى بيانات رقمية دقيقة مع الحفاظ على التخطيطات الأصلية.
❓ هل يمكن تشغيل الأداة داخل المؤسسات؟
نعم، بفضل رخصة MIT المفتوحة، يمكن تشغيل DeepSeek OCR على الخوادم المحلية أو عبر واجهات API آمنة.
❓ هل تدعم الأداة تحليل الجداول والمخططات؟
بالتأكيد، الأداة مصممة للحفاظ على البنية المعقدة للصفحات بما في ذلك الجداول والمخططات والمعادلات الرياضية والكيميائية.
❓ ما اللغات التي تدعمها الأداة؟
تدعم أكثر من 100 لغة تشمل اللغات اللاتينية والعربية والآسيوية والعلمية، ما يجعلها مناسبة للمشاريع العالمية.
❓ هل الأداة مجانية؟
نعم، DeepSeek OCR مفتوحة المصدر تمامًا ويمكن استخدامها وتخصيصها دون قيود.
الخلاصة
تُعتبر DeepSeek OCR ثورة حقيقية في عالم تحليل المستندات الرقمية والذكاء الاصطناعي البصري. بفضل دقتها العالية، وسرعتها الفائقة، ودعمها لمئات اللغات، وقدرتها على الحفاظ على تخطيط الصفحات الأصلي، فهي تتفوق على أدوات OCR التقليدية من جميع النواحي.
سواء كنت باحثًا، مطورًا، أو مؤسسة تبحث عن حلول رقمنة فعالة، فإن DeepSeek OCR تقدم لك مزيجًا مثاليًا من الأداء، والذكاء، والمرونة. إنها المستقبل الحقيقي لمعالجة الوثائق وفهمها بلغة الذكاء الاصطناعي.
أدوات مشابهة
Verex
مجاني + مدفوع

Cheat Layer
تجربة مجانية
Abstra workflows
مجاني + مدفوع
flutch.ai
مدفوع
AnySolve AI
تجربة مجانية
Godmode
اشتراك
Nextbrowser
تجربة مجانية

PixieBrix
مجاني + مدفوع
SayData
تجربة مجانية
Strawberry Browser
تجربة مجانية
AirWeave AI
مجاني + مدفوع
Cua AI
مجاني + مدفوع
احدث الاقسام المضافة
احدث الادوات

Translingo

DocTransGPT

CogVideo

ChatGPT Atlas
Makeup Check AI

Modamind
NightCafe Creator

Nightmare AI

Deepfake Maker AI Halloween

Trend IQ

GrokiPedia
Fanfun AI
Base44
Story Path
PlaylistAI
